Product
How SpendProxy works
SpendProxy is a reverse proxy that intercepts AI API traffic, calculates accurate costs, attributes spend to features automatically, and runs optimization engines to cut waste. All inside your infrastructure.
2-minute demo
See it in action
From wrong numbers to accurate cost control in one Docker container.
Architecture
Where SpendProxy sits in your stack
A transparent reverse proxy between your application code and AI providers. Your code changes one URL — everything else stays the same.
baseURL points to SpendProxy~/.spendproxy/localhost:4100/dashboardCost accuracy
How SpendProxy calculates true cost
Every provider handles billing differently. SpendProxy implements provider-specific logic instead of using a single formula that gets most cases wrong.
Cached token handling
prompt_tokens includes cached. Subtract cached_tokens before applying the input rate. Cache hits are billed at 50% of the input rate.
input_tokens excludes cached. cache_read_input_tokens and cache_creation_input_tokens are billed at separate rates. Most tools ignore this entirely.
promptTokenCount includes cached. Subtract cachedContentTokenCount before billing. Reasoning tokens (Gemini 2.5) are separated.
Reasoning token handling
Models like OpenAI o3/o4-mini and Gemini 2.5 Pro use internal reasoning tokens that are billed as output but never shown to the user. SpendProxy extracts reasoning_tokens from the response and bills them at the correct output rate, separate from visible completion tokens. Most tools either miss these entirely or double-count them.
Streaming accuracy
Full SSE streaming support for all three providers. For OpenAI, SpendProxy injects stream_options.include_usage automatically. For Anthropic, it parses message_start and message_delta events. For Google, it detects streaming endpoints and parses usageMetadata from chunks. Cost data is appended as an SSE comment — your client code doesn't change.
Optimization engines
5 engines that reduce spend automatically
Each engine operates independently in off, monitor, or autopilot mode. Monitor first to see the opportunity, then enable autopilot when you're confident.
Cache Injection
Detects prompts that would benefit from provider-level caching and enables it automatically. Works with OpenAI's prompt caching, Anthropic's cache control, and Google's cached content. No code changes needed — SpendProxy modifies the request before forwarding.
Response Deduplication
Identifies identical in-flight requests — common during frontend retries, parallel component renders, or webhook replays — and serves a single provider response to all callers. Eliminates redundant API calls without affecting your application logic.
Model Routing
Analyzes request complexity and routes simple tasks to cheaper models automatically. A lookup query doesn't need GPT-4.1 — SpendProxy downgrades it to GPT-4.1-mini transparently. Complex reasoning stays on the model you specified. Includes circuit breaker protection for model availability.
Budget Guardrails
Set spend limits per feature, team, or project. When a budget is hit, SpendProxy can warn (add a header), downgrade (switch to a cheaper model), or block (return a 429). No more surprise bills from a runaway agent loop.
Retry Storm Suppression
Detects retry cascades during provider outages — when your application hammers a failing API with exponential backoff across hundreds of instances. SpendProxy throttles the storm, serves cached responses where possible, and prevents a 2-minute outage from becoming a $5K bill.
Attribution
Automatic cost attribution without code changes
SpendProxy uses multiple signals from each request to automatically group costs by feature, agent, or workload type.
System prompt fingerprinting
Hashes the system prompt to create a stable fingerprint. Requests with the same system prompt are always grouped together, even across different users or sessions. Shows as chat:p-3f8a21b4 in the dashboard.
Toolset fingerprinting
Hashes the set of function tools attached to a request. Your code-review agent and your search agent get separate cost breakdowns automatically. Shows as agent:p-c72e:t-8f4a.
Workload classification
Detects the type of workload from the endpoint and request body: chat completion, agent call, embeddings, image generation, or audio. Each type is tracked separately.
SDK detection
Identifies the calling SDK from the User-Agent header: openai-python, anthropic-ts, langchain, vercel-ai, crewai, and more. Useful for understanding which parts of your stack drive costs.
Optional: explicit headers
You can also use manual headers for explicit control. They take priority over auto-detection.
Response cost headers
Every proxied response includes cost metadata.
Providers
Supported models
Fuzzy matching handles versioned model IDs automatically. Pricing database updated continuously.
OpenAI
Anthropic
Dashboard
Everything you need in one view
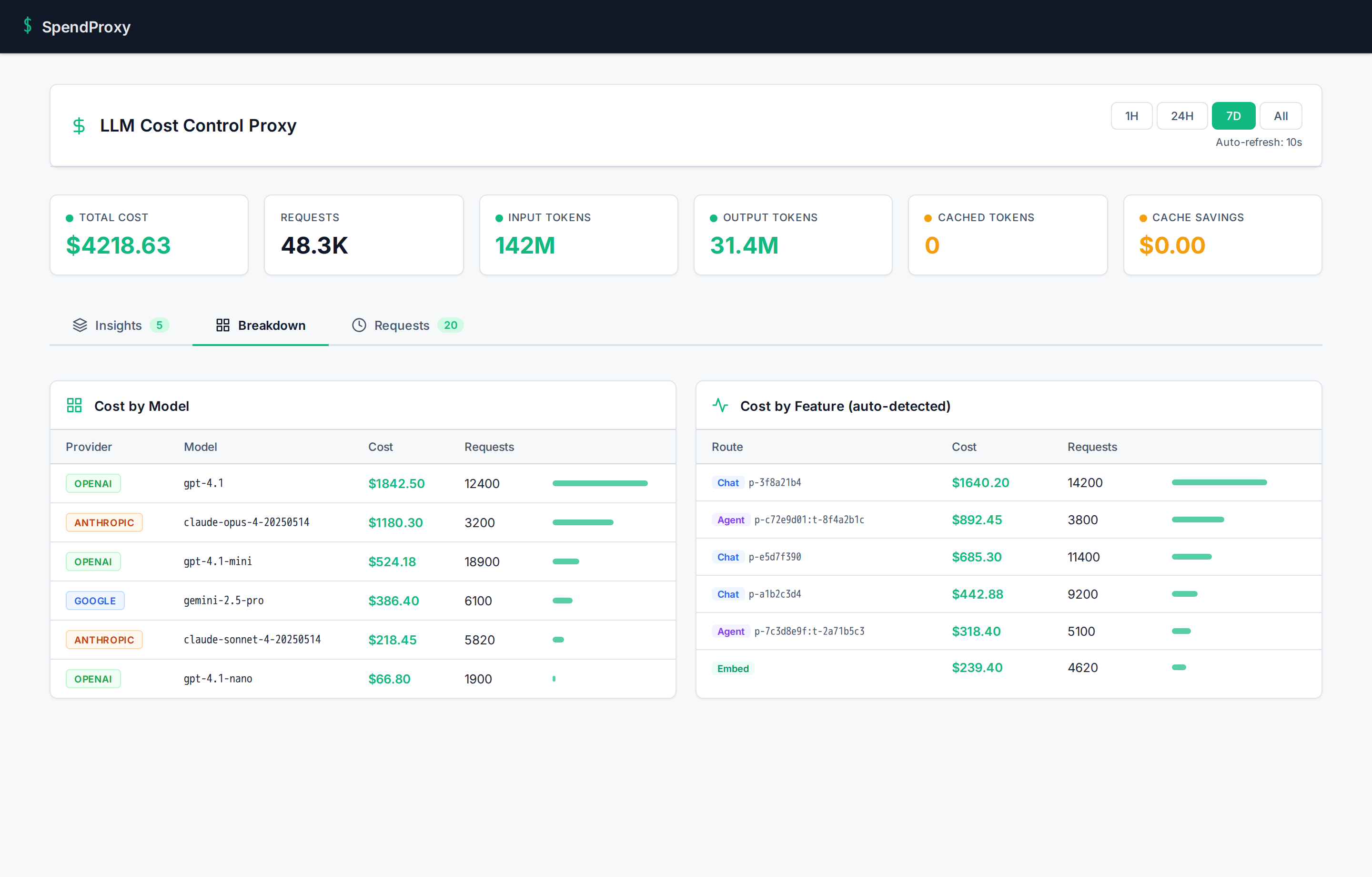
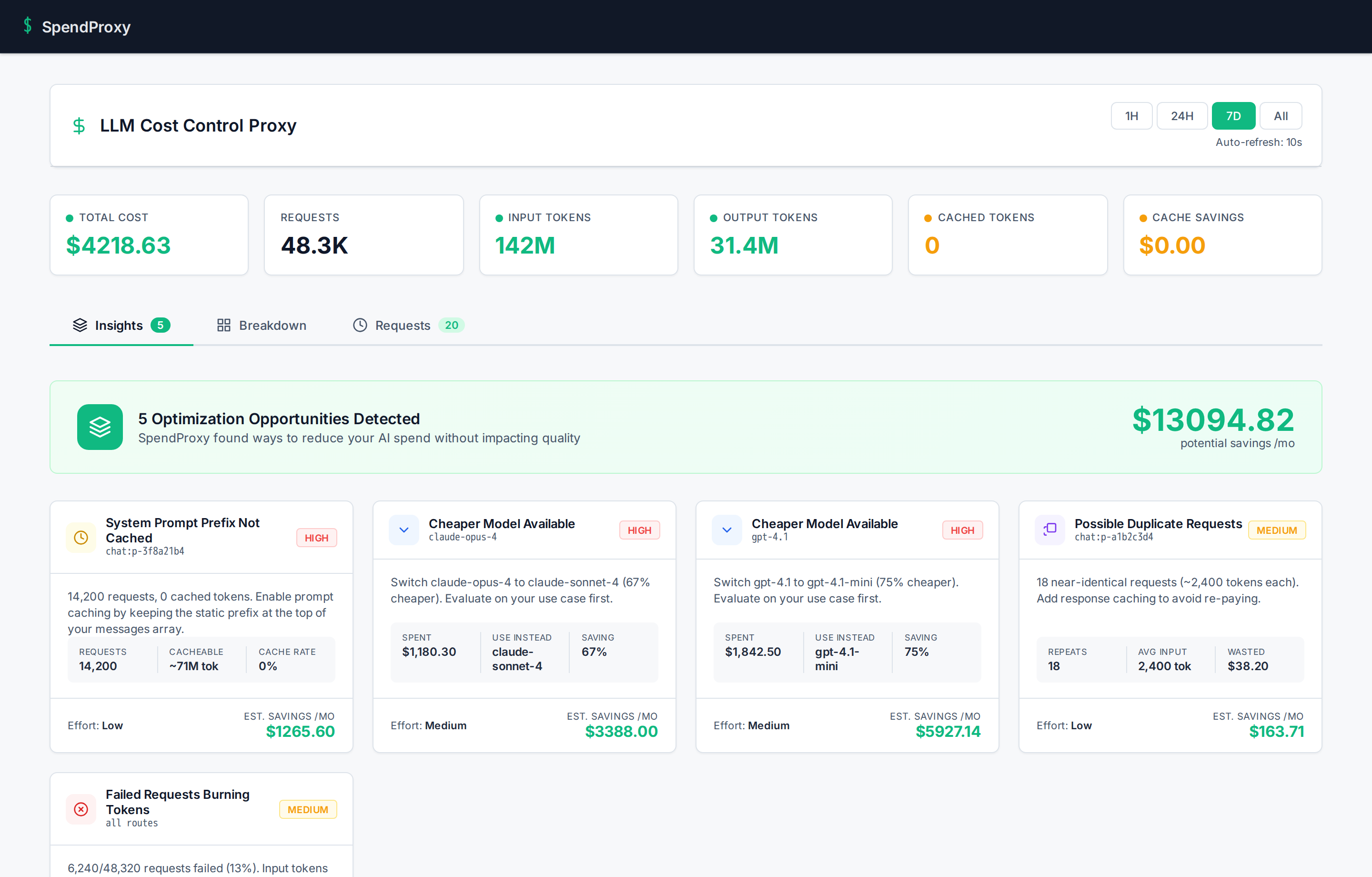
Cost breakdowns by model and feature, optimization insights with savings estimates, and full request-level detail. Auto-refreshes every 10 seconds.
Cost breakdown by model and auto-detected feature:
Optimization insights with estimated monthly savings:
See it in action
Book a 30-minute technical walkthrough. We'll show you the architecture, the accuracy engine, and how the optimization engines work on real traffic.
Book a Technical Walkthrough